我認為這是「黑色之物」...不是指視覺上的印象,不管將世上多少東西混在一起,都不會滲出這樣特異感。
「...第一次見到,這個世界...竟然還有『不是灰色的東西』。」-- <棺材,旅人,怪蝙蝠(6)>,きゆづきさとこ繪,季上元譯
"...LET ME BE FREE......I WILL NOT BE FORGOTTEN..."
-- in game Hollow Knight, by The Radiance
一開始就盤算好,強化學習的部份都該使用 python 語言/pytorch 框架進行,Rust 主要支援 server 的部份。在 2023 年八月我正式開設 PathogenEngine repo 之前,對應到 legacy 分支的內容即是一整個作為 server 的程式專案,而非現在 main 分支的函式庫型專案。
一路走來,拋棄的點子很多。今天用來描述一下遺留在 legacy 分支裡面的那些點子。
首先是 TUI 介面直接實作,使用 termion 的用法,其中也大幅參考自 Redox 的 ice 遊戲。主程式碼還可以在 board.rs 裡面的 Board::start() 方法找到。
現在還可以撈到歷史痕跡(這個直接玩有 bug,如果帶入 --load game_just_started.sgf 倒是有個設置完的棋盤樣貌,但是後續的控制和顯示都有問題),
$ git clone https://github.com/NonerKao/PathogenEngine --branch legacy
$ cd PathogenEngine; cargo run

如上,自行繪製格子、自行製作游標,甚至還將游標當作遊戲狀態的一個成員。當時曾經有一個很瘋狂的想法,就是如果是直接丟這個介面給代理人去試玩,會怎麼樣?也許只提供方向鍵(wasd 或 hjkl)和確認取消之類的兩、三個功能鍵。以現在的架構做一個對比,我們只有 examples/coord_client,就是因為只有實作 examples/coord_server 與之對應,使用直接可以對應到 SGF 欄位的座標值當作基本的行棋元素。原本來說,上述的極簡 UI 可以規劃出兩種不同的遊戲介面:
光是想像該怎麼把強化學習演算法兜到這兩種型態的代理人上面就很瘋狂也很有趣。但是我是在軟體工程這一關打了退堂鼓,後來沒再維護這個部份了。其實這時候已經有 core、board 解藕的意圖,但是不夠完整。
話說回到現在有的座標介面,雖然有些自動代理人的程式,但在寫作的此時還沒有實作可以遊玩的 UI,也許是來不及了吧。
說來慚愧,跨程式通訊那麼多步數,我最熟悉的還是只有 socket。在去年八月改組 repo 架構之後,就採用了伺服器對代表兩個玩家的客戶端的架構,其中並使用無添加任何協定的純 TCP 進行,實在陽春。相當於將整個遊戲化為嚴格的狀態機,每個時間點伺服器只能允許特定類型的輸入、只會回應特定格式的輸出,客戶端也不能亂講話,是很僵硬的一種模式。
更具體說(也許應該考慮補述在 Hacking.md 裡面,因為此前未曾以文件形式披露),他們的結構是類似
status_code.rs 裡面。跟隨著 4-byte 的狀態碼之後的就是透過 encode 編碼過的盤面狀態。這麼做是為了後續互動的強化學習代理人能夠方便紀錄輸入資料、並簡單處理之後就能夠轉成 torch.tensor。0~35 編碼了遊戲棋盤座標,36~61 編碼了羅盤座標,252~255 則編碼了特殊指令。但這還是很不夠。比方說,現在是由 server 負責寫出棋譜,而一般的 SGF 其實可以紀錄賽果(這個還不難,現在有做)、紀錄雙方棋手(試想,在一個高度自動化的強化學習代理人互相博奕的競技場,我哪有時間去手動標記哪些是由哪兩組 model 進行的對局...)。
另一例,前述的特殊指令 255 其實代表詢問合法步數,這也是兩個參照用的非 ML-based 代理人 random_agent.py 和 query_agent.py 的最大差異:前者就是一直試,如果失敗了就會得到失敗的狀態碼,下一次猜測就總之將之從候選步數中去除;後者則每一次決策之前都先下 255 取得合法步數,再從中隨機挑選棋步。但,試想後期代理人若是訓練得宜,通常來說都會下出合乎規則的棋步的時候,我又何必這樣事必躬親的詢問 server 呢?
總之,現在支援的雙方對話方法,都像是咬合得剛剛好的齒輪,沒有其他空間可以應對其他需求。gPRC 與否,其實也不是重點,也或許過於殺雞用牛刀,但重點是想要一套機制可以很方便定義,好讓兩造對話內容性質不相同時,能夠有不同的框架來包含。
不過我倒是有請 ChatGPT 提供一套 Server in Rust, Client in Python 的範例程式碼框架,也是很簡單就能夠套用,只是目前沒有力氣將之派上用場。依經驗,過程中的 dependency 小問題是不可避免的(無論要增列在 Cargo.toml 或是用 pip 補安裝 ),但也都可以直接跟它抱怨相依性缺漏,而它也會有能力補上。是,理論上可以在一開始詢問的時候就請它確保相依性、安裝、路徑等零碎小問題不存在。
這實在是太教人心虛了...寫作的此時也還沒處理,應該也是來不及了。
簡單來說,就是我在遊戲引擎的處理,將遊戲分成不同的階段,
pub enum Phase {
Setup0, // Humanity and Underworld
Setup1, // Plague to put the 4 markers
Setup2, // Put characteres on the board
Setup3, // Doctor to put the marker on the map
Main(u32),
End(u32),
}
其中的開局階段與後續的標準回合是完全不一樣的執行邏輯,而這樣的不對稱性在其他部件都很難應對。
比方說,雖然還沒有正式介紹,但總之這些自我進化的代理人程式需要吃的訓練資料,也是用它們自己做大量蒙地卡羅模擬的對局資料。圍棋的話,每一步都非常對稱,黑白輪流,只要是縱橫交叉就可以落子,但這裡如此不對稱,無力對處;另外針對這整個 Phase 的處理在遊戲引擎內也是刻了好一陣子的狀態機才讓它可以用。無論如何,總之這些開局階段,最後被我當作一塊特別的部份完全獨立處理。在 examples 資料夾裡面,因此有針對開局的三個範例,
setup_generator:隨機產生開局。這個部份和實體遊戲也有所不同。實體遊戲的人間冥界版塊拼接並沒有相同的模式,但是我在遊戲引擎中的隨機生成部份有可能隨機出一樣的模式。但理論上不會產生太過遠離設計師意圖的盤面,因為我有確保每一個 3x3 版塊裡面都沒有任何行列是完全由人間或冥界單獨佔據的連通狀態。事實上,這個部份也是讓 ChatGPT 直接產生的小程式。但另外一個沒有足夠理解的技術點是 Rust 裡面使用 thread-safe 亂數產生器的方式,所以這個沒有平行化。不過好在,生成開局並不太花時間。setup_evaluator:使用同一個開局,給定指定的執行次數(也就是執行幾場基於這個開局的遊戲),並隨機產生棋步,統計勝率如何。這是我有強大棋感或是已經訓練出強大的 AI 代理人之前,唯一能夠定量評估開局的平衡度與好壞的方法。這也對應到下一個範例。setup_predictor:有了上述黑盒子,我們就可以大量運行,然後將那些開局--勝率收集成資料集。這個 example 其實不是 Rust,只是這可以視作在幫之後的強化學習代理人打頭陣。因為我在購買參考書之前,完全不知道 AlphaZero 或 AlphaGo 他們是用怎麼樣的類神經網路結構,才有辦法讓它學會。此前,我的強化學習經驗只有 OpenAI Gym 的 CartPole,而那個案例是全部可以用 FC(完全連接)層做的。自己兜架構應該不可能成功。無論如何,使用 10+ 殘差層(Residual block)的 ResNet 結構之後,預估起來還算接近,也就建立了基本的神經網路結構的信心。昨天發完文之後將所得的對局資料用以訓練。過去都沒有有系統的執行訓練和資料收集、紀錄結果,今天的收穫就是在 run 出一些習慣之後,終於比較多能夠探索超參數(hyperparameter)的機會,也用新的一批資料找到了更小一點的神經網路結構。
根據參考書的內容,AlphaZero 的網路架構就直接是 ResNet。輸入維度是 17x19x19,第一組模組是 256 個 3x3 filter 的卷積層(Convolution Layer),第二組是 19 個殘差塊(Residual Block,ResNet 的基本架構,也可參考我用於這個專案的實作),最後有兩組輸出,策略(362 = 361 個可選擇的著點 + 1 虛手)與價值(一個 -1 ~ 1 之間的值代表盤面的價值)。
相較於過去的幾個世代,今天試出了一個僅使用 8 組殘差塊、每組內的卷積層的頻道數量僅有 108 個的版本,比先前嘗試的量小了些,不無小補地節省一些訓練和推論的時間。它雖然是從頭開始訓練,但表現上也能夠和先前累積了兩三個世代的模型相稱。今天就以這兩張截圖作結:
從訓練集的損失程度(越高表示損失越多,表示模型從這個資料集學會的東西越非直接對應)看來,的確 8x108 的新模型(橘色)比不上先前已經好幾個世代(紅色與亮藍色是兩組不同超參數的模型的代表)的,相較之下貼平,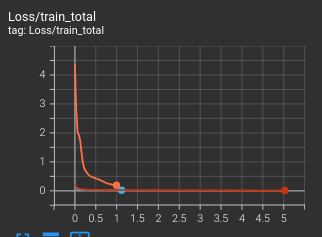
但是從測試集的損失程度看來,橘色的卻又非常成功地能夠將它學會的知識應用在測試集當中,很早期就能夠與兩組前輩交叉。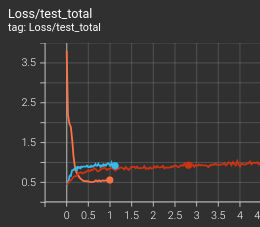
這個系列的遊戲雜談與系統雜談部份應該會延續到第十日出頭。進到強化學習部份之後,也或許會再有一篇「放棄的點子 -- 續」之類,畢竟後來也還是在放棄一些想法才能繼續前進。也或許在後續文章的當日「目前狀況」中分段慢慢提及。

